学习使用Apache Hive
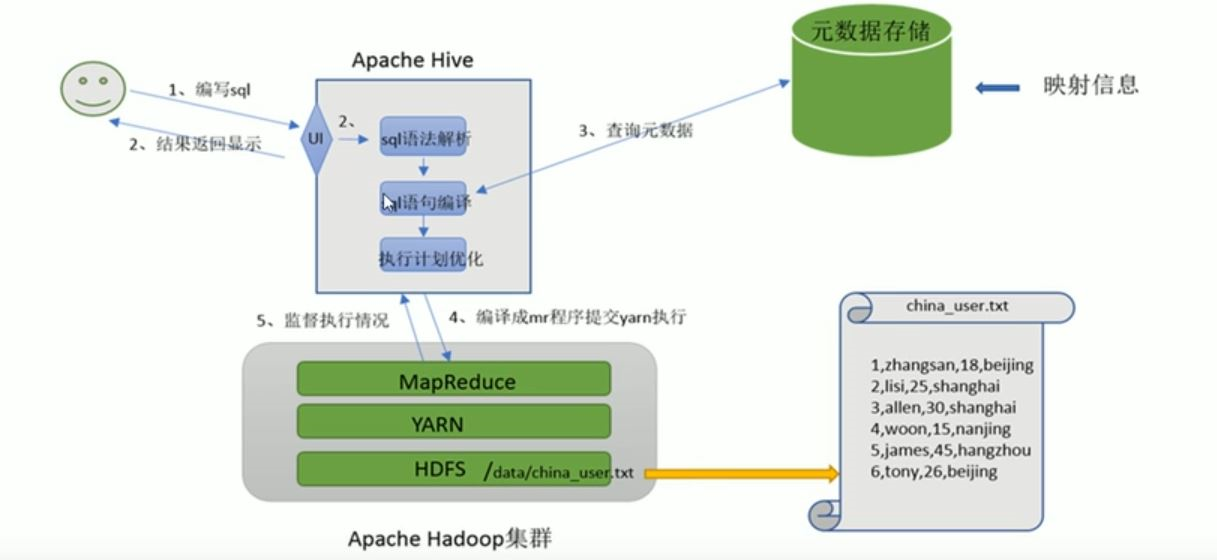
HIVE的作用
将数据文件映射为一张表。
将SQL语法解析编译成为MapReduce的执行程序。
HIVE的组件
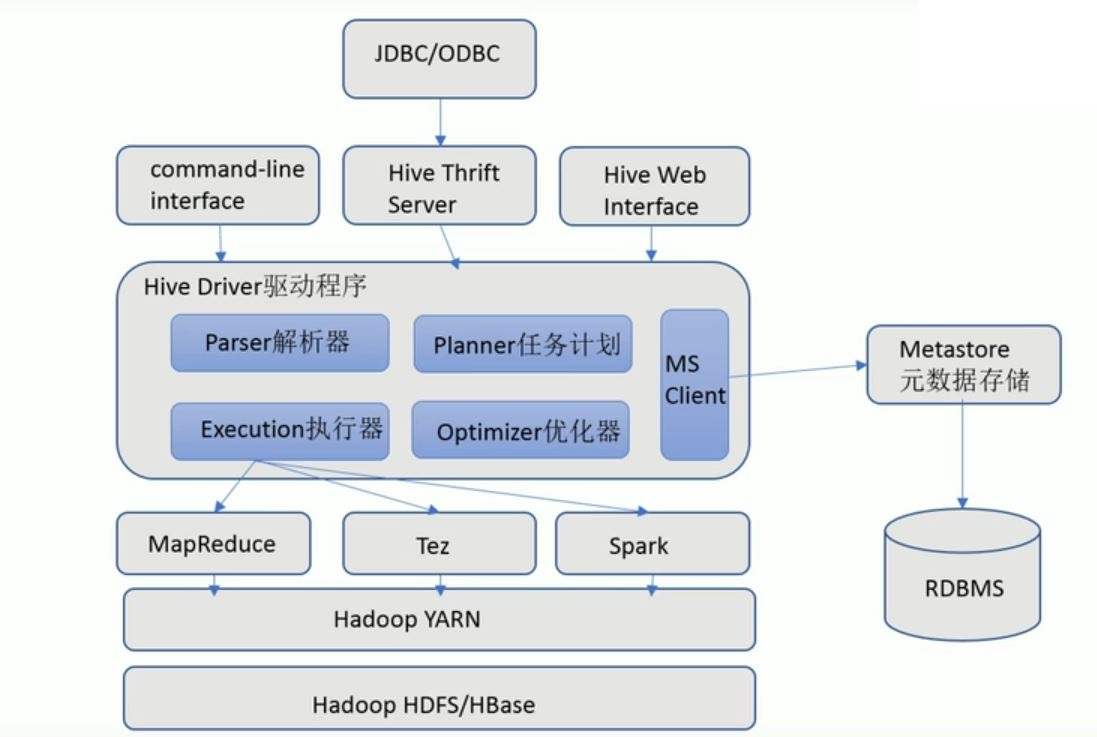
1.用户接口
包括CLI,JDBC/ODBC、WebGUI。
CLI(Command Line Interface)即命令行,是Hive的默认模式。
HIVE中的Thrift服务器允许外部客户端通过网络与Hive交互,类似于JDBC或ODBC协议。(JDBC/ODBC即Java数据库连接,是Hive的默认模式。
WebGUI是Hive的Web界面,提供给用户友好的操作界面。
2.元数据存储
通常是存储在关系数据库如MySQL、Postgresql等。
3.解释器
将SQL转换为MapReduce任务,最后提交给Hadoop执行。
4.编译器
将SQL编译成可以运行的MapReduce程序。
5.优化器
优化MR程序,转换为执行效率更高的执行计划。
6.执行器
提交MR程序给Hadoop执行,然后返回结果。HIVE支持Mapreduce、Tez和Spark三种执行引擎。
Hive数据模型
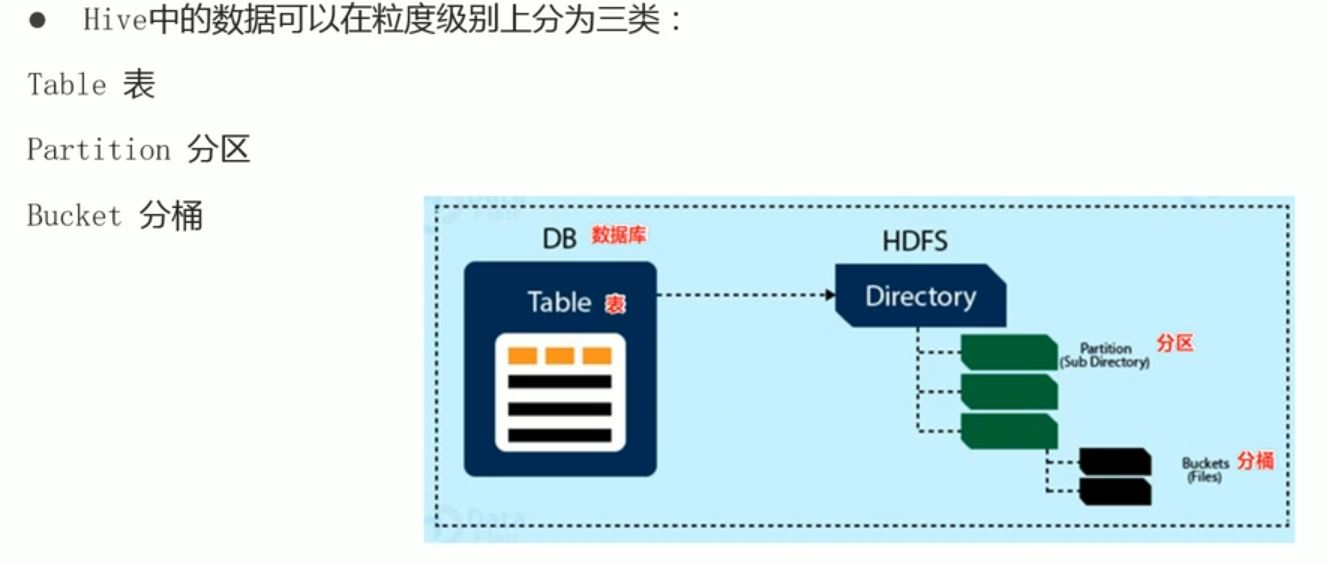
HIVE中的数据模型分为三层:
1.元数据
元数据存储在关系数据库中,如MySQL、Postgresql等。
2.内部表
内部表是Hive默认的表类型,数据存储在HDFS中。
3.外部表
外部表是用户自定义的表类型,数据存储在HDFS中,但元数据存储在Hive的元数据存储中。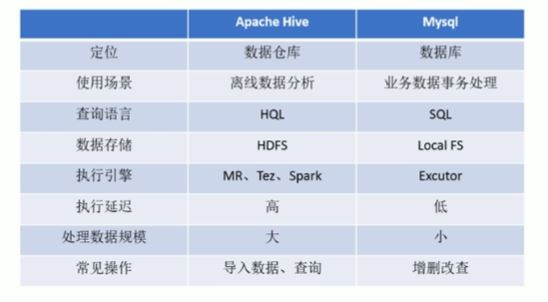
Hive Metadata
Hive Metadata存储在关系数据库中,如MySQL、Postgresql等。
Hive Metadata存储了Hive 创建的database、表及其位置、类型、字段顺序等。
Hive Metastore
元数据服务,作用是管理Hive Metadata。对外暴露服务地址,让各种客户端通过连接Metastore服务,由Metastore再去连接数据库存取元数据。
好处:多个客户可同时连接;客户不知道数据库账号密码,保证元数据安全。
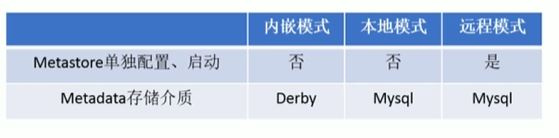
Metastore的配置方式
内嵌模式、本地模式、远程模式。
区分方式:
1.是否需要启动Metastore服务?
2.Metadata是存储在内置的数据库(如Derby)中还是远程数据库(如MySQL、Postgresql)中?