Hadoop搭建之完全分布式运行模式
起因:
课题组的服务器的大数据集群是好几年前的师兄们安装配置,并由星环公司提供技术服务,因此对基本的大数据环境搭建并不熟悉。这篇文章就是记录从头开始搭建Hadoop的生产环境,并记录遇到的问题和解决过程。
准备工作:
1.四台虚拟机zzyhadoop01\02\03\04,系统CentOS7,配置好IP
2.JDK和Hadoop的软件包
3.Linux远程连接工具Xshell和文件传输工具Xftp
配置开始:
02号机已经安装好JDK和Hadoop,使用scp(secure copy,安全拷贝)将JDK和Hadoop复制到03、04号机上。
命令1
2
3
4
5
6
7
| [root@zzyhadoop02 ~]# scp -r /opt/module/jdk1.8.0_212 root@zzyhadoop03:/opt/module
[root@zzyhadoop03 ~]# scp -r atguigu@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/
[root@zzyhadoop03 ~]# scp -r atguigu@hadoop102:/opt/module/* atguigu@hadoop104:/opt/module
##上述所在主机不同,要分清从哪里拿文件,送到哪里去
## scp -r $pdir/$fname $user@$host:$pdir/$fname
## 命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
|
rsync远程同步工具
1
2
3
| rsync -av $pdir/$fname $user@$host:$pdir/$fname
|
同步环境变量到03、04
1
2
3
| xsync /etc/profile.d/my_env.sh #同步
source /etc/profile #执行同步后的文件,添加路径
|
脚本代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| #!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in zzyhadoop02 zzyhadoop03 zzyhadoop04
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
|
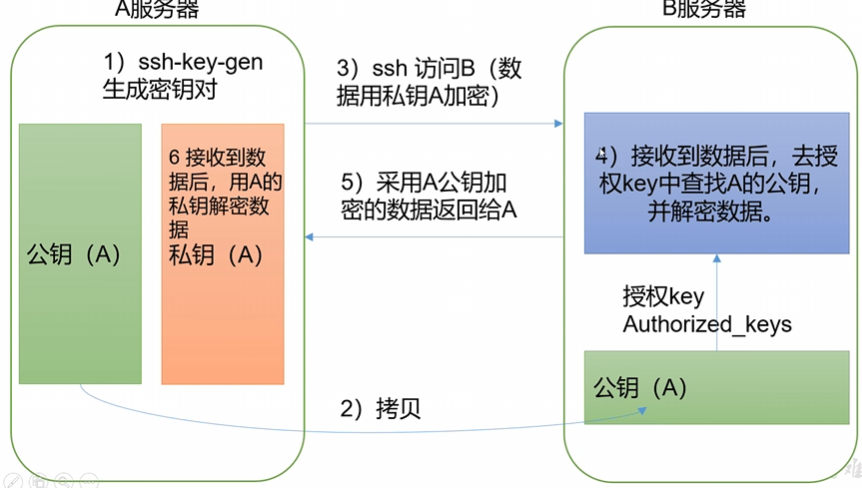
免密登陆,方便传输配置文件。
集群配置
NameNode和SecondaryNameNode不要安装在同一台服务器
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
配置要求如下。

自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,根据项目需求重新进行修改配置。
02号机配置完成后,配置workers,内容为三台机器的名称。最后运行xsync脚本分发给其他机器。
启动集群
集群是第一次启动,需要在zzyhadoop02节点格式化NameNode.
1
2
3
| ##zzyhadoop02节点
hdfs namenode -format ##格式化NameNode
sbin/start-dfs.sh ##启动HDFS
|
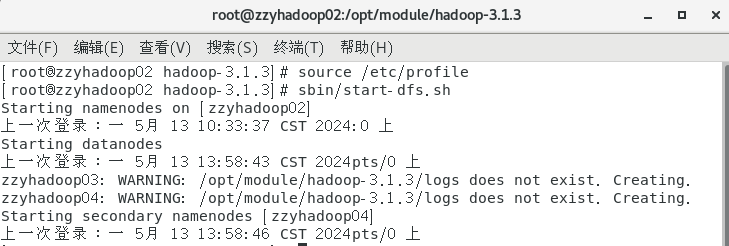
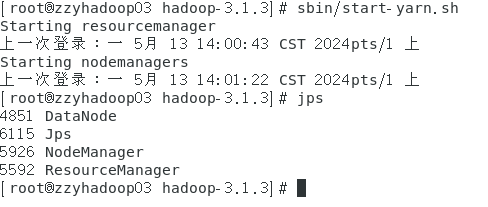
接下来可以在Web端查看HDFS的NameNode。
浏览器中输入:zzyhadoop02:9870即可查看HDFS上存储的数据信息
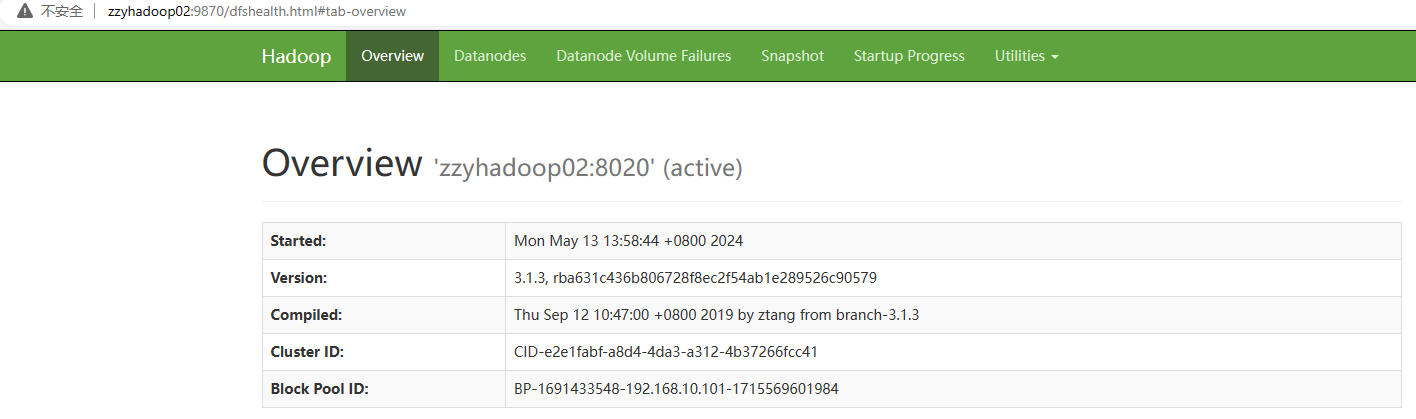
总结
先配置虚拟机,到下载JDK和Hadoop,配置集群,最后启动。整体过程相对顺利,对Hadoop框架的三大内容HDFS(分布式文件系统)、YARN(计算资源管理)和MapReduce(计算引擎)有了更新的认识。接下来对YARN和MapReduce的学习不可或缺。为了方便后续的学习,再配置一下历史服务器和日志的聚集,向MR编程进发!