Hadoop之HDFS
Hadoop三大件之Hive
HDFS的背景和意义
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS(Hadoop Distributed File System)只是分布式文件管理系统中的一种。其他还有诸如 Amazon S3 (Simple Storage Service)、Google Cloud Storage、Microsoft Azure Blob Storage等。
HDFS(Hadoop Distributed File System),用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
HDFS的优缺点
优点:
1.高容错性:数据自动保存多个副本
2.大数据处理:数据规模大,能达到TB甚至PB级别的数据;文件规模大,能达到百万文件数量。
3.可靠性和经济性:可构建在普通计算机上,通过多副本机制提高可靠性。
缺点:
1.无法做到低延时数据访问。
2.无法高效对大量小文件存储。
3.不支持并发写入、文件随机修改。(仅支持数据append)
HDFS组成架构
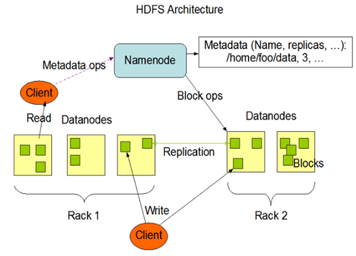
NameNode(NN):
(1)管理HDFS的名称空间;
(2)配置副本策略;
(3)管理数据块(Block)映射信息;
(4)处理客户端读写请求。
DataNode:
(1)存储实际的数据块;
(2)执行数据块的读写操作。
Client:
(1)文件切分,文件上传后被切分为Block,然后进行上传。
(2)与NameNode交互,获取文件的位置信息。
(3)与DataNode交互,读取或写入数据。
(4)提供一些命令来管理HDFS,比如NN的格式化和访问HDFS。
Secondary NameNode:
(1)辅助NameNode,分担其工作量。(比如定期合并Fsimage和Edits,并推给NN)
(2)紧急情况下,可辅助恢复NameNode。
文件块(Block):HDFS中的文件在物理上是分块存储,大小一般为128或256M。与磁盘传输速率相关。
HDFS的Shell命令
上传命令:
-moveFromLocal:从本地剪切粘贴到HDFS
-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
-put:等同于copyFromLocal,生产环境更习惯用put
-appendToFile:追加一个文件到已经存在的文件末尾
下载命令:
-copyToLocal:从HDFS拷贝到本地
-get:等同于copyToLocal,生产环境更习惯用get
HDFS的写数据流程
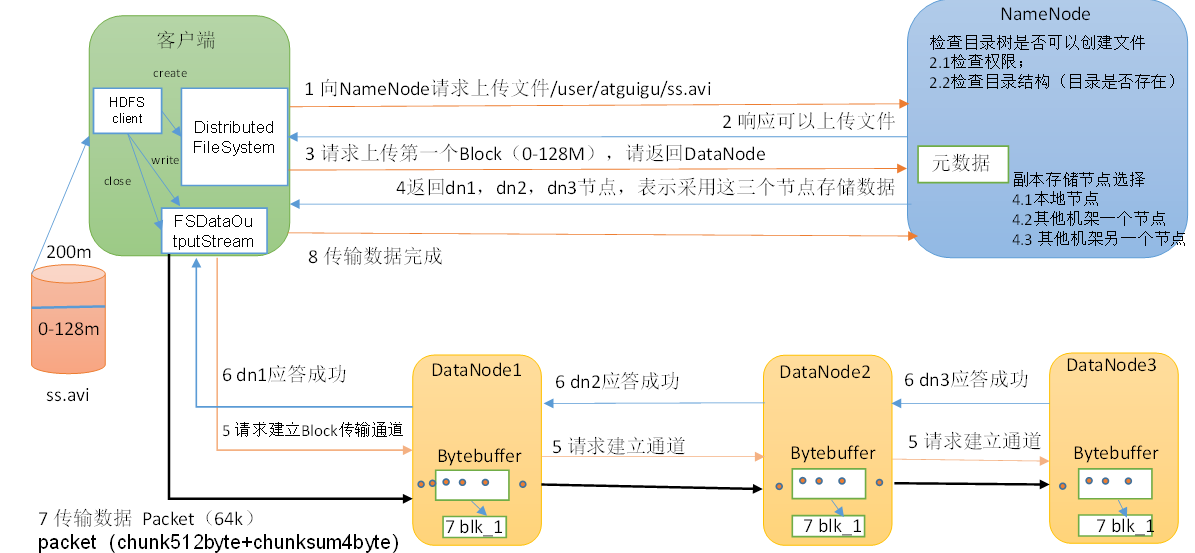
(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
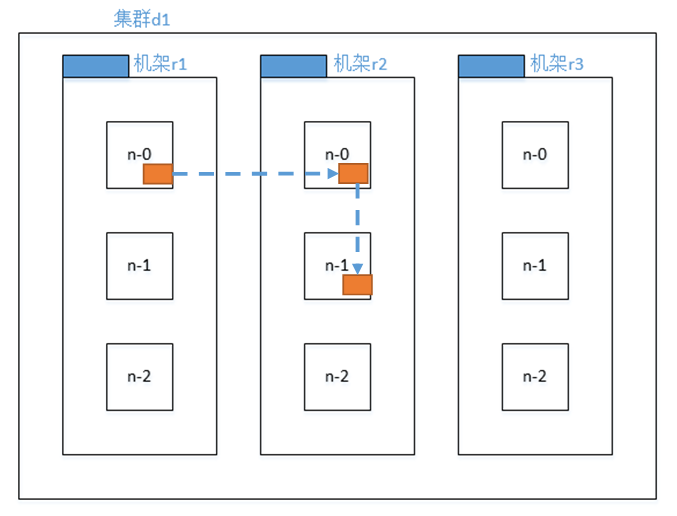
副本节点选择
第一个副本在Client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本在另一个机架的随机一个节点。
第三个副本在第二个副本所在机架的随机节点。
HDFS读数据流程
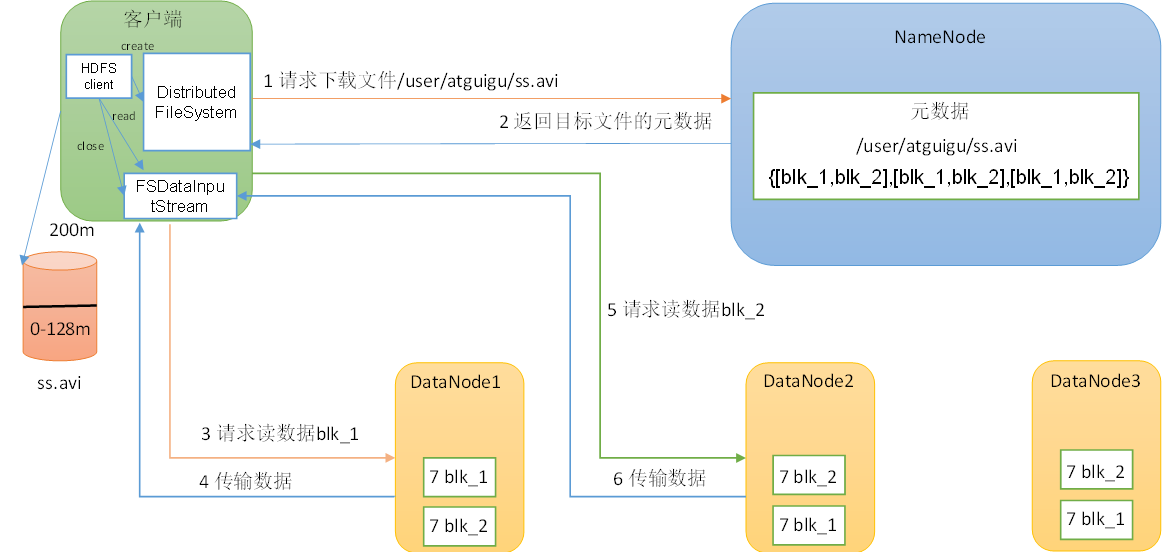
(1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
(3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
(4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
NameNode工作机制
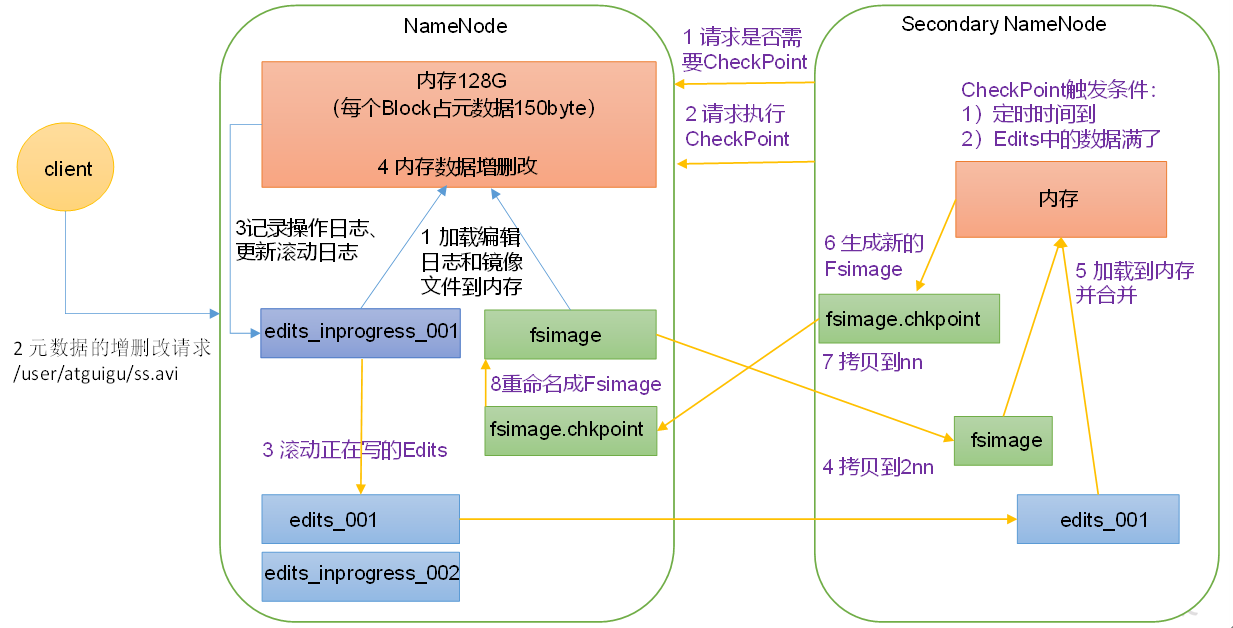
1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
DataNode工作机制
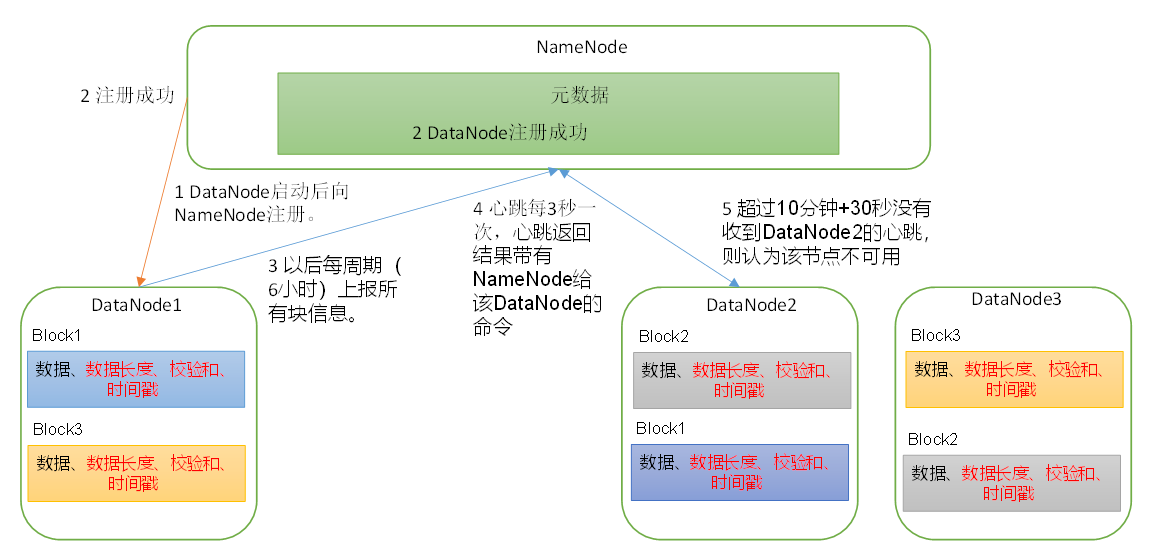
(1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2)DataNode启动后向NameNode注册,通过后,周期性(6小时)的向NameNode上报所有的块信息。
DN向NN汇报当前解读信息的时间间隔,默认6小时。
(3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
(4)集群运行中可以安全加入和退出一些机器。
结语
针对HDFS的学习集中在各个组成部分的工作机制,而对里面的细节没有深入,比如Fsimage和Edits的解析。后续在生产环境再深入学习吧。HDFS组成部分间的成员角色和工作流程诠释了分布式文件系统分块存储的特点,同时兼顾传输效率和可靠性!