Hadoop的计算执行模块MapReduce
MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
优点:
1.MapReduce易于编程
2.良好的扩展性
3.高容错性
4.适合PB级以上海量数据的离线处理
缺点:
1.不擅长实时计算
2.不擅长流式计算(Sparkstreaming、Flink)
3.不擅长DAG(有向无环图)计算(Spark)
MapReduce核心思想
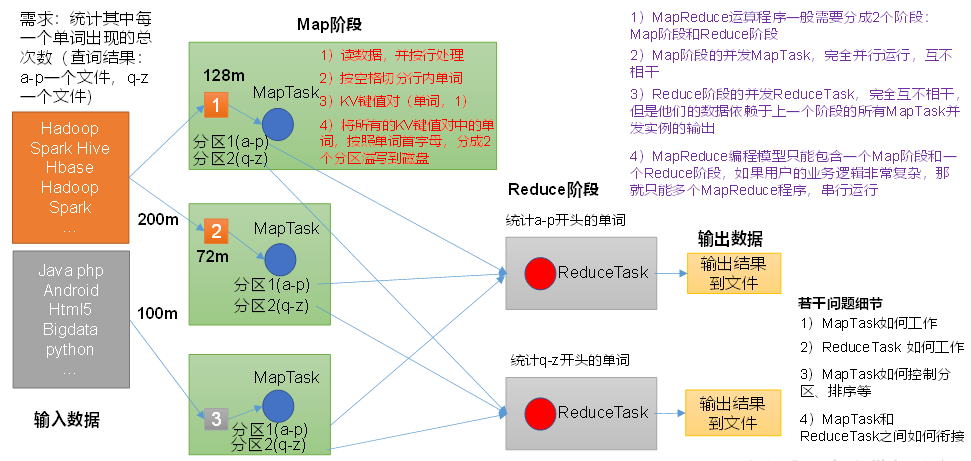


一个完整的MapReduce程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责Map阶段的整个数据处理流程。
(3)ReduceTask:负责Reduce阶段的整个数据处理流程。
序列化
1)什么是序列化
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
2)为什么要序列化
一般来说,“活的”对象只生存在内存里,关机断电就没有了。而且“活的”对象只能由本地的进程使用,不能被发送到网络上的另外一台计算机。 然而序列化可以存储“活的”对象,可以将“活的”对象发送到远程计算机。
3)为什么不用Java的序列化
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效传输。所以,Hadoop自己开发了一套序列化机制(Writable)。
4)Hadoop序列化特点:
(1)紧凑 :高效使用存储空间。
(2)快速:读写数据的额外开销小。
(3)互操作:支持多语言的交互.